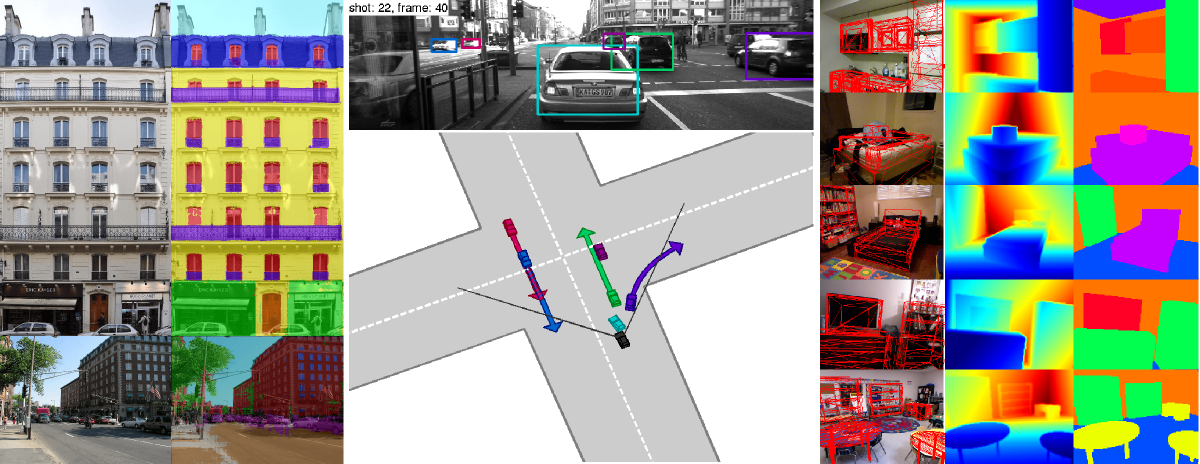
Left: Facade parsing using auto-context [ ]. Center: Recovering 3D urban scene layout while estimating and associating all objects in the scene [ ]. Right: Indoor scene understanding from a single RGB-D image using 3D CAD priors [ ].
Holistic scene understanding is an important prerequisite for many indoor and outdoor applications, including autonomous driving, navigation, indoor and outdoor mapping as well as localization. Given a high-dimension input (e.g., image or video stream), the task is to extract a rich but compact representation that is easily accessible to subsequent processing stages. Typical outputs comprise semantic information [ ] or 3D information about the shape and pose of objects and layout elements in the scene [ ]
In [ ], we present novel probabilistic generative models for multi-object traffic scene understanding from movable platforms which reason jointly about the 3D scene layout as well as the location and orientation of objects in the scene. In particular, the scene topology, geometry and traffic activities are inferred from short video sequences. Inspired by human driving capabilities, our models do not rely on GPS, lidar or map knowledge. Instead, we take advantage of a diverse set of visual cues in the form of vehicle tracklets, vanishing points, semantic scene labels, scene flow and occupancy grids. Our approach successfully infers the correct layout in experiments on varied videos of 113 challenging intersections.
In [ ], we propose a model which infers 3D objects and the layout of indoor scenes from a single RGB-D image captured with a Kinect camera. In contrast to existing holistic scene understanding approaches, our model leverages detailed 3D geometry using inverse graphics and explicitly enforces occlusion and visibility constraints for respecting scene properties and projective geometry. We cast the task as MAP inference in a high-order conditional random field which we solve efficiently using message passing. Our experiments demonstrate that the proposed method is able to infer scenes with a large degree of clutter and occlusions.
In [ ], we propose a system for the problem of facade segmentation. Building facades are highly structured images and consequently most methods that have been proposed for this problem, aim to make use of this strong prior information. In this work, we propose a system which is almost domain independent and consists of standard segmentation methods. A sequence of boosted decision trees is stacked using auto-context features. We find that this, albeit standard, technique performs better, or equals, all previous published empirical results on all available facade benchmark datasets.