3D deep learning suffers from a cubic increase in memory. To address this problem, we have developed a data-adaptive framework for discriminative and generative convolutional neural networks which allows 3D recognition, segmentation and reconstruction at resolutions up to $256^3$ voxels.
We live in a three-dimensional world, thus understanding our world in 3D is important. A first step towards this 3D understanding is to accurately reconstruct our environment based on 2D image measurements or sparse 3D point clouds. We have developed novel representations, algorithms and benchmarks for this task.
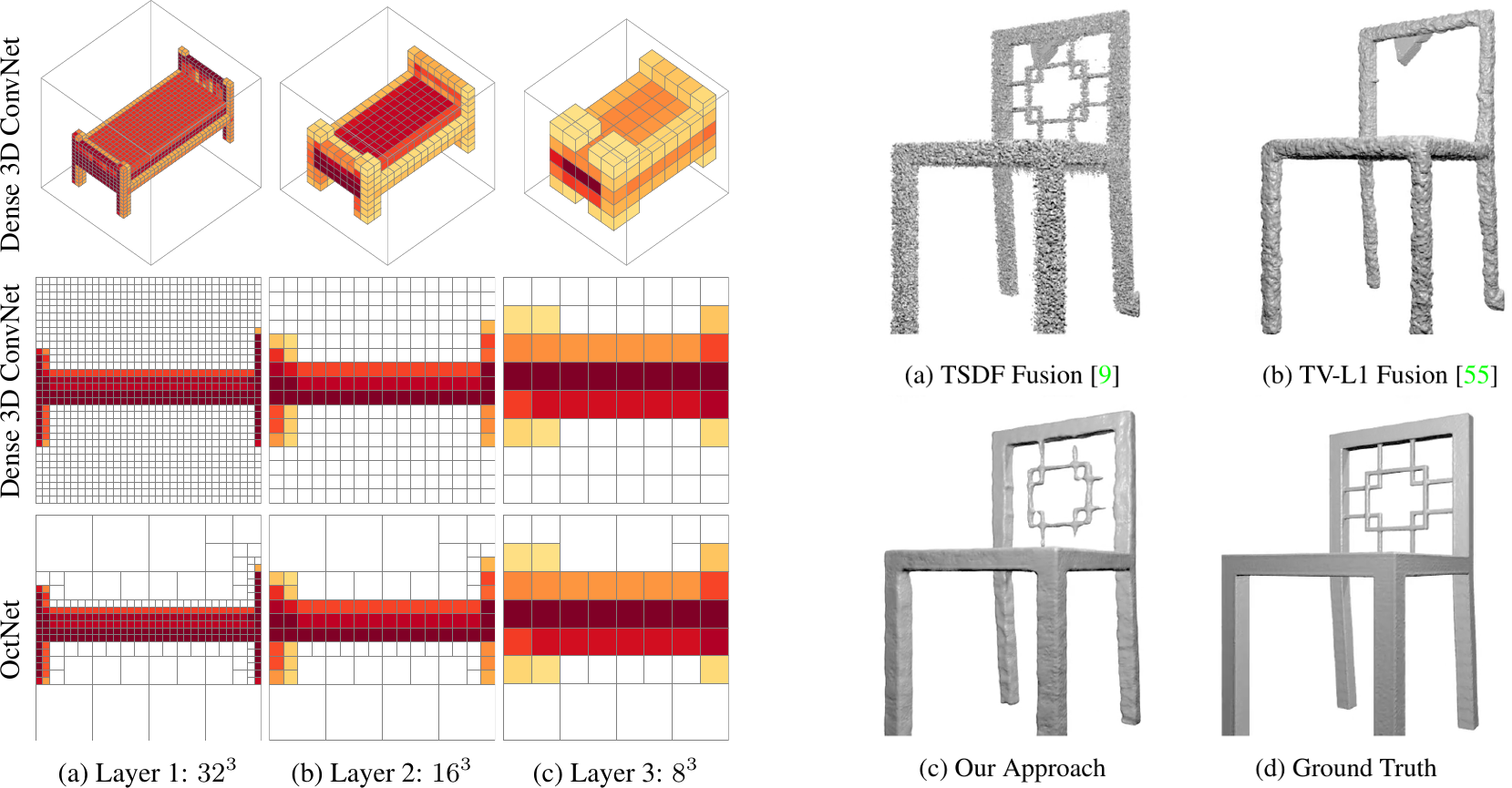
As 3D reconstruction is an ill-posed inverse problem, solving it requires strong a-priori knowledge or models that incorporate 3D shape information from training data. Towards this goal, we have developed OctNet, one of the first frameworks for scaling notoriously memory-hungry 3D deep learning techniques to high-resolution input and output spaces, allowing for detailed volumetric 3D reconstructions at $256^3$ voxels and beyond as illustrated in the figure above.
While generic convolutional neural networks are agnostic to the image formation process, classical approaches to 3D reconstruction leverage explicit knowledge about 3D geometry and light propagation.
With RayNet, we have presented the first approach that integrates this knowledge into a deep 3D reconstruction model by unrolling a high-order CRF as layers in a convolutional neural network.
In similar spirit, we have presented a technique to reconstruct geometry and semantics jointly using a deep variational reconstruction approach.
To go beyond voxel representations, we have developed Deep Marching Cubes, a deep neural network that outputs mesh representations of arbitrary topology. In contrast to prior work, our model can be trained end-to-end to predict meshes without resorting to auxiliary representations (e.g., TSDFs) and loss functions.
Point clouds are another popular output representation. However, they lack connectivity and topology. To tackle this problem, we have presented novel approaches to depth map completion using sparse convolutions and 3D shape completion.
Access to 3D datasets and benchmarks is crucial for driving progress in the field. Beyond our popular KITTI dataset, we have therefore proposed novel large-scale datasets for single image depth prediction and depth map completion as well as the ETH3D benchmark for two-view and multi-view 3D reconstruction in indoor and outdoor environments. Our evaluation servers with held-out ground truth provide the basis for a fair comparison.










