While deep learning undeniably achieves impressive results for numerous different computer vision tasks, the theoretical foundations behind the success of these methods are often not well understood. One particular focus of our group is on deep generative models which are important for understanding the principles of vision, for building robust models and for training high-capacity deep neural networks.
Variational Autoencoders (VAEs) represent a particular class of latent variable models that can be used to learn complex probability distributions from training data. However, the quality of the results crucially relies on the expressiveness of the inference model. Towards this goal, we introduced Adversarial Variational Bayes (AVB), a technique for training Variational Autoencoders with arbitrarily expressive inference models by introducing an auxiliary discriminative network that allows to rephrase the maximum-likelihood-problem as a two-player game.
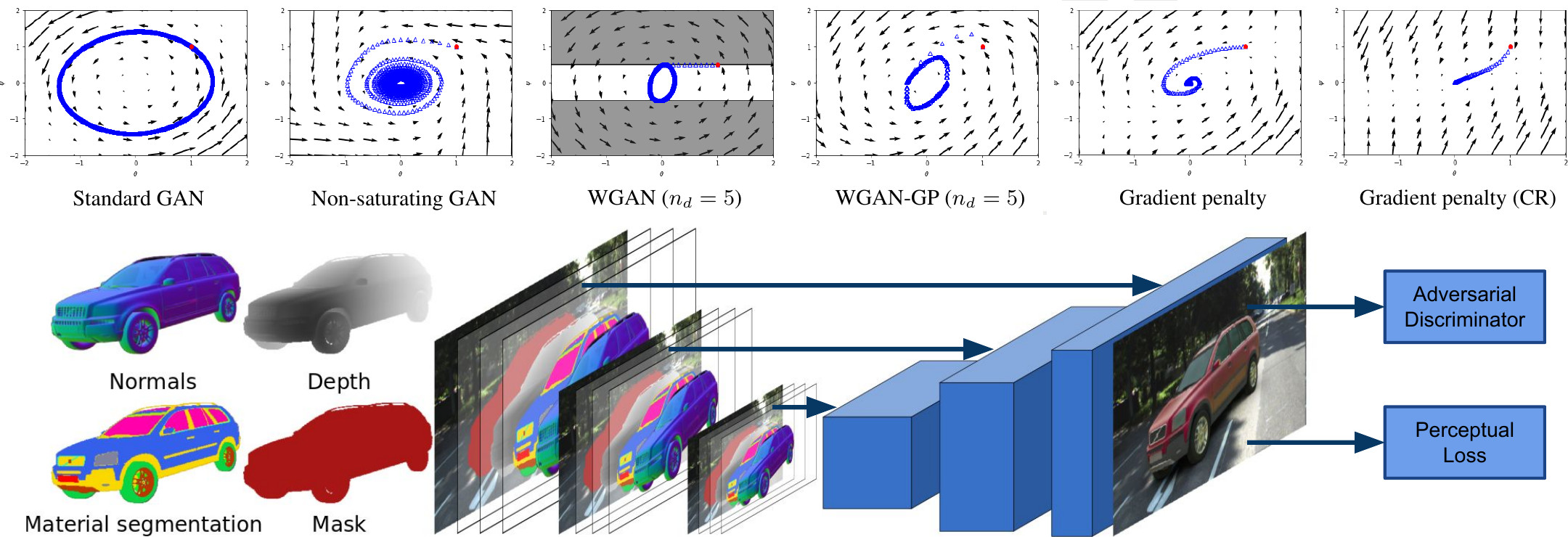
We have also analyzed the optimization problems underlying recent Generative Adversarial Networks (GANs). In particular, we analyzed the gradient vector field associated with the GAN training objective using the formalism of smooth two-player games. Using our findings, we developed a new algorithm with better convergence properties. We also showed that the requirement of absolute continuity is necessary for convergence of unregularized GAN training using a simple counterexample. We further analyzed which GAN training methods converge and proved local convergence for GAN training with simplified gradient penalties.
We leveraged our insights on training generative models for tackling image synthesis tasks, with the ultimate goal of generating large amounts of training data at limited cost. With Augmented KITTI, we first demonstrated that data augmentation is a viable alternative to annotating real images or synthesizing entire scenes from scratch. Towards this goal, we augmented real images from the KITTI dataset with photo-realistically rendered 3D car models, yielding significant performance improvements when used for training deep neural networks on recognition tasks.
Our work on Geometric Image Synthesis demonstrated that the rendering process itself can be learned. In particular, we used the output of OpenGL (depth, normals, materials) as input to a neural network which generates a rendering of the respective real-world object. Importantly, our generative model handles ambiguity in the output (e.g., cars might have different color) and learns to add realistic transparency, reflection and shadowing effects to the augmented objects.


